人类在NLP领域的研究已长达半世纪,现在AI终于扬眉吐气了!5月4日,在斯坦福大学的会话问答(CoQA)挑战赛中,AI的会话能力已媲美人类,并以0.6分优势全面“碾压”人类水平!也就是说,人类与这个模型互动更像是与真人之间的交流。
CoQA挑战赛通过理解文本段落,并回答对话中出现的一系列相互关联的问题,来衡量机器的性能。此次,微软亚研院NLP团队和微软Redmond语音对话团队联手组成黄金搭档参赛。
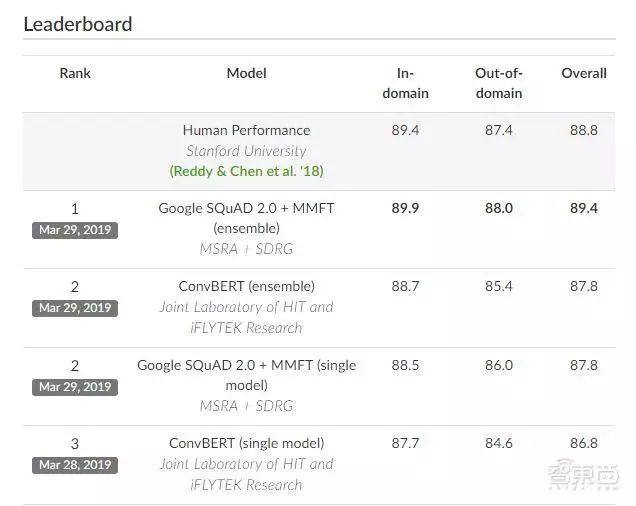
在CoQA挑战赛历史上,他们是唯一一个在模型性能方面达到人类水平的团队!他们于2019年3月29日提交的集合系统得分对应域内、域外和整体F1分别为89.9 / 88.0 / 89.4,而同一组会话问题和答案的人类表现则分别为89.4 / 87.4 / 88.8。
从2018年至今,人类在NLP领域不断有好消息传来。去年10月谷歌推出BERT语言模型在11项NLP任务中夺得STOA结果。今年2月,OpenAI展示了其训练的一个大规模的无监督语言模型GPT-2,可以根据前文进行续写,并且不需要特定训练。
这也说明了,当下NLP研发正进入一个黄金时期!

微软再度赢得斯坦福CoQA挑战赛
CoQA是一个大规模的会话式问答数据集,这些问答数据来自不同领域的文章中,机器学习通过从这些文章中提取问答数据进行会话问答。CoQA挑战的目的,是为了衡量机器对文本的理解能力,检验机器在接近人类的对话中回答问题能力的高低。
NLP团队之前使用斯坦福SQuAD(问题答疑数据集)在CoQA领域内数据集上F1得分超过80%的模型,达到80.7%,在对话系统模型性能挑战赛中刷新最佳性能纪录。与SQuAD相比,CoQA中的问题更具会话性,答案可以是自由格式文本,以确保对话中答案的自然性。
CoQA中的会话问题形式是模仿人类的对话,但一般都很短。进行第一个问题之后的每个问题都根据第一个问题来进行问答,这使得简短问题对于机器解析更加困难。例如,假设您向系统提问,“谁是微软的创始人?”当您提出后续问题“他什么时候出生?”时,机器解析需要判断现在谈论的仍然是同一主题。

根据CoQA排行榜,NLP和SDRG模型取得的成绩再次刷新了记录,机器阅读理解已成功达到人类水平。
这项成就意味着Bing等搜索引擎和Cortana等智能助手与人们的互动可以通过这种模型以更自然的方式提供信息,就像人与人之间相互沟通一样。

微软模型如何“碾压”人类?
为了更好地测试现有模型的泛化能力,CoQA从七个不同的领域收集数据,儿童故事、文学、中学和高中英语考试、新闻、维基百科、Reddit和科学。其中前五种类型的文章用于模型的训练、开发和测试集,后两种仅用于测试集。
CoQA使用F1(统计学中衡量二分类模型精确度的指标)指标来评估性能。F1评分衡量模型系统的实际问答效果和预测情况之间的平均单词重叠。域内F1根据与训练集相同的域的测试数据进行评分;并对来自不同域的测试数据评分域外F1。总体F1是整个测试集的最终得分。
微软研究人员使用了一种训练模型的策略,模型系统从几个相关任务中学习,并将信息用于改进目标机器阅读理解(MRC)任务。

在这种多阶段、多任务的微调方法中,研究人员首先在多任务设置下从相关任务中学习MRC相关背景信息,然后在目标任务上微调模型,并使用语言建模在两个阶段中辅助完成任务,以帮助减少会话式问答模型的过度拟合。
NLP和SDRG的策略起到了有效的作用,他们的机器模型在CoQA挑战赛中的强大表现进一步证明了这一点。

走过半世纪,人类在NLP领域取得十大里程碑
NLP是人工智能领域的一个重要子领域,同时也是一种非常吸引人的人机交互方式,从50年代机器翻译和人工智能研究算起,NLP至今有长达半个世纪的历史了。
在过去的二十多年里,科学家们利用统计机器学习方法,让NLP技术不断向前迈进。
近四年来,深度学习则给NLP带来了新的学习模式。其中在单句翻译、抽取式阅读理解、语法检查等任务上,更是达到了可比拟人类的水平。
细数半个世纪以来,人类在NLP领域有着十大里程碑,分别是:
1、1985复杂特征集
2、1966词汇主义
3、1976统计语言模型
4、2001神经语言模型(Neural language models)
5、2008多任务学习(Multi-task learning)
6、2013词嵌入
7、2013RNN/CNN用于NLP的神经网络
8、2014序列到序列模型(Sequence-to-sequencemodels)
9、2015注意力机制和基于记忆的神经网络
10、2018预训练语言模型
从2018年至今,人类在NLP领域不断有好消息传来。
去年10月谷歌推出BERT语言模型,通过在33亿文本的语料上训练语言模型,最终BERT在11项NLP任务中夺得STOA结果,在自然语言处理学界以及工业界都引起了不小的热议。
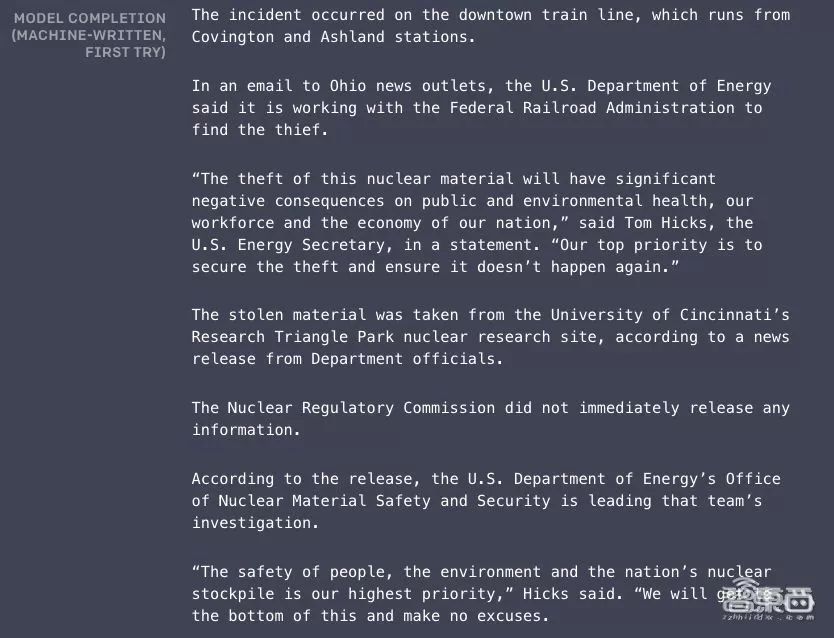
▲OpenAI GPT-2编造的新闻
今年2月,OpenAI展示了其训练的一个大规模的无监督语言模型GPT-2,具有来自800万个网页的15亿数据集,其训练目标就是基于前面给定的文本,从而预测接下来的文字。它可以生成连贯的文本段落,并进行阅读理解、机器翻译、问答和撰写摘要,并且所以这些AI能力都不需要特定任务的训练。

结语:NLP研发正迎来黄金时期
在此次比赛中,由微软亚研院NLP团队和微软Redmond语音对话团队在比赛中已经让模型在性能方面达到人类水平,这也标志着微软可以在搜索引擎和语音助手等与人们强交互领域可以更自然地互动和提供信息。
自然语言理解被誉为被誉为“人工智能皇冠上的明珠”,其进步必将会推动人工智能整体进展。从目前来看,随着深度学习技术的应用,人类在NLP领域正不断取得进步,更多有趣、惊人的AI在陆续出现,NLP研发也正迎来又一个黄金时期。

